
AI 전문가가 되고싶은 사람
사이킷런 사용 ( Perceptron 알고리즘 ) 본문
모든 경우에 뛰어난 성능을 낼 수 있는 분류 모델은 없기에 최소한 몇개의 학습 알고리즘 성능을 비교하고 문제에 최선인 모델을 선택하는 것이 권장된다. 특성이나 샘플의 개수, 데이터셋에 있는 잡음 데이터의 양과 클래스가 선형적으로 구분되는지 아닌지에 따라서도 다르다.
* 사이킷런에서 제공하는 붓꽃 데이터셋을 사용 ( 시각화를 위해 두개의 특성만 사용 )
from sklearn import datasets
import numpy as np
iris = datasets.load_iris()
X = iris.data[:,[2:3]]
y = iris.target● train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=1, stratify=y)X와 y는 각각 훈련 데이터, 테스트 데이터이다.
● test_size
- 훈련, 테스트 데이터를 어떤 비율로 나눌 것인지 결정 ( 0.3 -> 훈련 70%, 테스트 30% )
- 보통 0.2 혹은 0.3의 값을 사용하고, 데이터셋의 크기가 클 경우 0.1을 사용하는 경우도 있다.
● random_state
데이터셋을 분할 전 무작위로 섞기 때문에 radom_state를 통해 고정해두면 실행 결과를 재현할 수 있다.
● stratify
y로 설정할 경우 계층화 기능을 사용하여 훈련 데이터셋과 테스트 데이터셋의 클래스 레이블 비율을 입력 데이터 셋과 동일하게 설정하는 것이다.
ex) [50 50 50] -> train : [35 35 35], test:[15 15 15]
● StandardScaler
* 스케일링하는 이유
- 아래와 같이 특성 간의 범위 차이가 클 경우 나이보다 소득이 훨씬 더 큰 영향을 주게 된다.
- 특성 A: 나이 (범위: 0-100)
- 특성 B: 소득 (범위: 1000-100000)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
● StandardScaler의 fit 메서드 ( 평균 0, 표준편차 1 )
- 훈련 데이터셋의 각 차원마다 샘플의 평균과 표준편차를 계산한다. 이후 transform 메서드를 호출하여 계산된 평균과 표준편차를 통해 훈련 데이터셋을 표준화한다.
- 그 다음 훈련 데이터셋과 테스트 데이터셋의 샘플이 서로 같은 비율로 이동되도록 동일한 평균과 표준편차를 통해 테스트 데이터셋을 표준화한다.
● Perceptron
from sklearn.linear_model import Perceptron
# eta0 : 학습률 , random_state : 그대로 재현되도록 난수 설정
ppn = Perceptron(eta0=0.1, random_state=1)
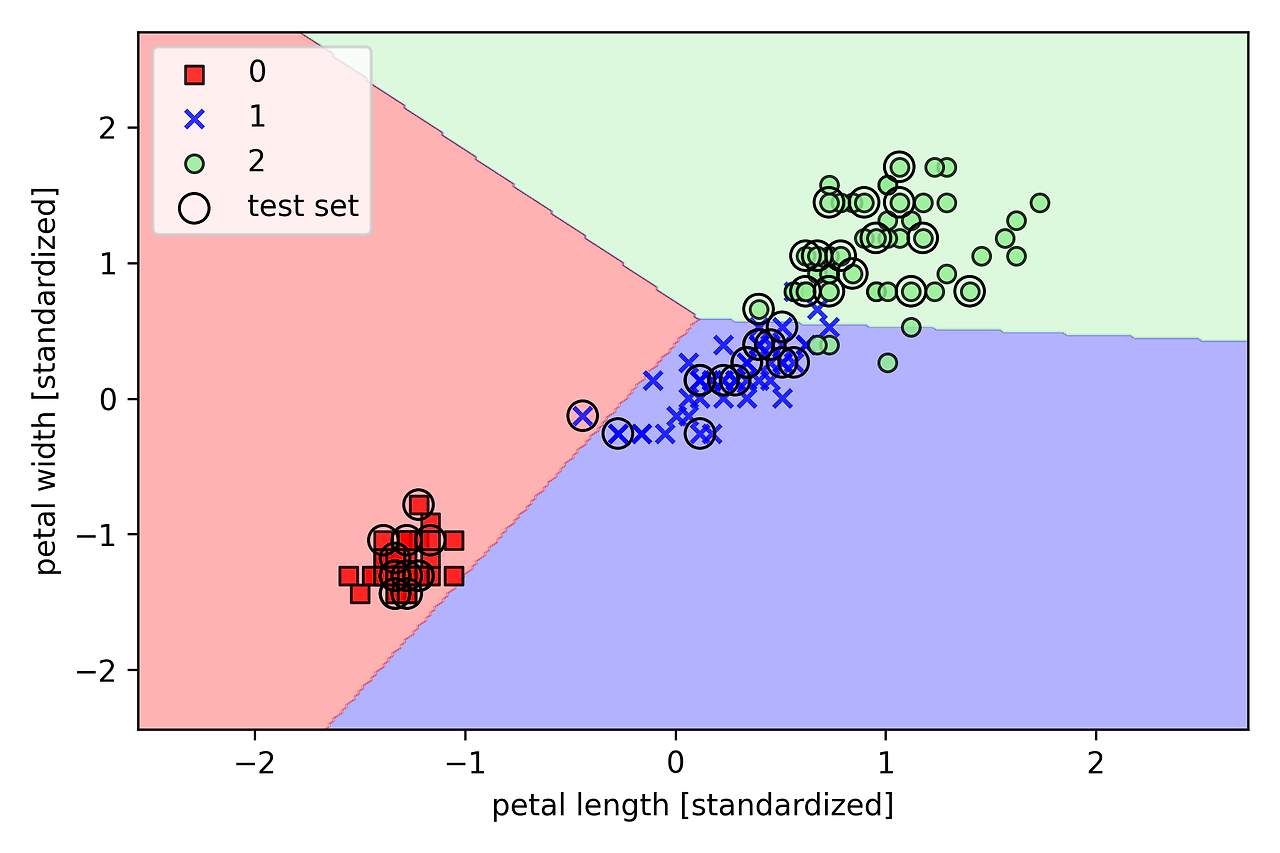
ppn.fit(X_train_std, y_train)y_pred = ppn.predict(X_test_std)이에 대한 결과로 45개의 샘플 중 1개를 잘못 분류하고 있다. 퍼셉트론의 경우 선형적으로 구분되지 않는 데이터셋에 수렴하지 못한다. 선형적이지 않는 데이터셋에 사용할 시 에포크마다 적어도 하나의 샘플이 잘못 분류되기 때문에 가중치 업데이트가 끝도 없이 계속된다
'머신러닝 교과서' 카테고리의 다른 글
| 아달린 (Adaline) - 적응형 선형 뉴런 (실습) (0) | 2024.08.04 |
|---|---|
| 아달린 (Adaline) - 적응형 선형 뉴런 (0) | 2024.08.03 |
| 퍼셉트론 학습 알고리즘 구현 (0) | 2024.08.03 |
| 인공 뉴런 ( 퍼셉트론 이해하기 ) (1) | 2024.08.03 |
| PyTorch 학습을 통한 머신러닝 및 취업 준비 (0) | 2024.08.03 |



