
Notice
Recent Posts
Recent Comments
Link
12-20 17:12
AI 전문가가 되고싶은 사람
(구현) Going deeper with convolutions 본문
논문에서 제시해준 파라미터를 사용하여 구현을 해보았다. 주석을 하나하나 달아서 추후에 보게 될 때 바로 이해할 수 있도록 하였다.
참고사이트 : https://sahiltinky94.medium.com/know-about-googlenet-and-implementation-using-pytorch-92f827d675db
Know about GoogLeNet and implementation using Pytorch
Hi Guys! In this blogs, I will share my knowledge, after reading this research paper, what it is all about! Before I proceed it, I want…
sahiltinky94.medium.com
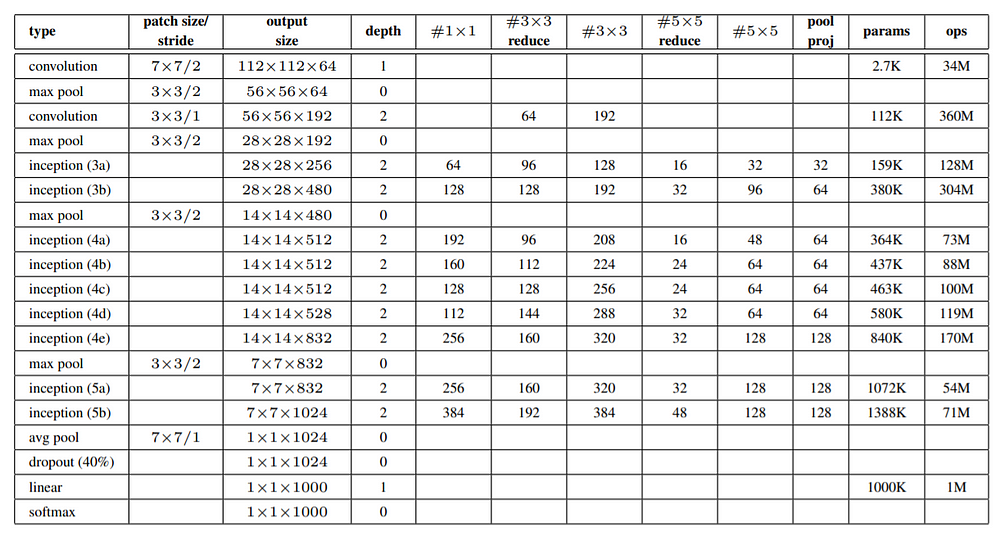
import torch
import torch.nn as nn
# 기본적인 합성곱 연산 처리하는 블록
class ConvBlock(nn.Module):
def __init__(self, in_fts, out_fts, k, s, p):
super(ConvBlock, self).__init__()
self.convolution = nn.Sequential(
# 입력채널수, 출력채널수, 커널사이즈, 스트라이드, 패딩
nn.Conv2d(in_channels=in_fts, out_channels=out_fts, kernel_size=(k,k), stride=(s,s), padding=(p,p)),
nn.ReLU()
)
def forward(self, input_img):
# 입력 이미지를 convolution 블록에 통과
x = self.convolution(input_img)
return x
# 두 단계의 합성곱 연산을 포함한 블록
# 첫 단계에서 1x1 합성곱을 통해 입력 채널 수를 줄인 후, 두 번째 단계에서 주어진 커널 크기를 통해 더 복잡한 특징 추출
class ReduceConvBlock(nn.Module):
def __init__(self, in_fts, out_fts_1, out_fts2,k,p):
super(ReduceConvBlock,self).__init__()
self.redConv = nn.Sequential(
nn.Conv2d(in_channels=in_fts, out_channels=out_fts_1, kernel_size=(1,1),stride=(1,1)),
nn.ReLU(),
nn.Conv2d(in_channels=out_fts_1, out_channels=out_fts_2, kernel_size=(k,k), stride=(1,1),padding=(p,p)),
nn.ReLU()
)
def forward(self,input_img):
x = self.redConv(input_img)
return x
# 보조 분류기 정의
class AuxClassifier(nn.Module):
# num_classes : 분류할 클래스의 개수
def __init__(self, in_fts, num_classes):
super(AuxClassifier, self).__init__()
self.avgpool = nn.AvgPooll2d(kernel_size=(5,5), stride(3,3))
self.conv = nn.Conv2d(in_channels=in_fts, out_channels=128, kernel_size=(1,1), stride=(1,1))
self.relu = nn.ReLU()
# 완전 연결 층
self.fc = nn.Linear(4 * 4 * 128, 1024)
self.dropout = nn.Dropout(p=0.7)
# 1024개의 입력을 받아 num_classes 수만큼 출력하는 완전 연결 층
self.classifier = nn.Lineare(1024, num_classes)
def forward(self,input_img):
# 학습 시 한 번에 처리할 이미지 수
N = input_img.shape[0]
# 평균 풀링 연산으로 크기를 줄이고, 중요한 특징 추출
x = self.avgpool(input_img)
# 1x1 합성곱을 적용하여 채널 수 변환
x = self.conv(x)
x = self.relu(x)
# 피처 맵을 1차원으로 펼쳐 완전 연결 레이어에 입력할 준비
x = x.reshape(N, -1)
x = self.fc(x)
x = self.dropout(x)
x = self.classifier(x)
return x
# Inception 아키텍처
# 입력된 특징 맵에 대해 여러 크기의 필터(1x1,3x3,5x5)와 풀링 연산을 병렬로 적용한 후 연결하는 구조
class InceptionModule(nn.Module):
# 여러 필터와 풀링 계층 초기화하는 부분
def __init__(self, curr_in_fts, f_1x1, f_3x3_r, f_3x3, f_5x5_r, f_5x5, f_pool_proj):
super(InceptionModule,self).__init__()
# 1x1 합성곱 레이어 정의
self.conv1 = ConvBlock(curr_in_fts, f_1x1, 1, 1, 0)
# 3x3 합성곱 수행 레이어
self.conv2 = ConvBlock(curr_in_fts, f_3x3_r, f_3x3, 3, 1)
# 5x5 합성곱을 수행하는 레이어
self.conv3 = ConvBlock(curr_in_fts, f_5x5_r, f_5x5, 5, 2)
# 풀링 계층을 사용해 공간차원을 줄이고, 그 후 1x1 합성곱을 사용해 차원을 조정
self.pool_proj = nn.Sequential(
nn.MaxPool2d(kernel_size=(1,1),stride=(1,1)),
nn.Conv2d(in_channels=curr_in_fts, out_channels=f_pool_proj, kernel_size=(1,1), stride=(1,1)),
nn.ReLU()
)
def forward(self,input_img):
out1 = self.conv1(input_img)
out2 = self.conv2(input_img)
out3 = self.conv3(input_img)
out4 = self.pool_proj(input_img)
# 1x1, 3x3, 5x5 합성곱과 풀링의 결과들을 채널 방향으로 연결
x = torch.cat([out1, out2, out3, out4], dim=1)
return x
class MyGoogLeNet(nn.Module):
def __init__(self, in_fts=3, num_class=1000):
super(MyGoogLeNet, self).__init__()
self.conv1 = ConvBlock(in_fts, 64, 7, 2, 3)
self.maxpool1 = nn.MaxPool2d(kernel_size=(3,3), stride=(2,2), padding=(1,1))
self.conv2 = nn.Sequential(
ConvBlock(64,64,1,1,0),
ConvBlock(64,192,3,1,1)
)
self.inception_3a = InceptionModule(192,64,96,128,16,32,32)
self.inception_3b = InceptionModule(256, 128, 128, 192, 32, 96, 64)
self.inception_4a = InceptionModule(480, 192, 96, 208, 16, 48, 64)
self.inception_4b = InceptionModule(512, 160, 112, 224, 24, 64, 64)
self.inception_4c = InceptionModule(512, 128, 128, 256, 24, 64, 64)
self.inception_4d = InceptionModule(512, 112, 144, 288, 32, 64, 64)
self.inception_4e = InceptionModule(528, 256, 160, 320, 32, 128, 128)
self.inception_5a = InceptionModule(832, 256, 160, 320, 32, 128, 128)
self.inception_5b = InceptionModule(832, 384, 192, 384, 48, 128, 128)
self.aux_classifier1 = AuxClassifier(512, num_class)
self.aux_classifier2 = AuxClassifier(528, num_class)
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(7,7))
self.classifier = nn.Sequential(
nn.Dropout(p=0.4),
nn.Linear(1024*7*7, num_class)
)
def forward(self, input_img):
N = input_img.shape[0]
x = self.conv1(input_img)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool1(x)
x = self.inception_3a(x)
x = self.inception_3b(x)
x = self.maxpool1(x)
x = self.inception_4a(x)
out1 = self.aux_classifier1(x)
x = self.inception_4b(x)
x = self.inception_4c(x)
x = self.inception_4d(x)
out2 = self.aux_classifier2(x)
x = self.inception_4e(x)
x = self.maxpool1(x)
x = self.inception_5a(x)
x = self.inception_5b(x)
x = self.avgpool(x)
x = x.reshape(N, -1)
x = self.classifier(x)
if self.training == True:
return [x, out1, out2]
else:
return x
'논문' 카테고리의 다른 글
'논문' Related Articles
more


