
AI 전문가가 되고싶은 사람
[KT 에이블스쿨 기자단] 8주차 회고 본문
국회의원 선거날을 기준으로 전 날에는 자동차 파손 여부를 분류하는 모델을 개발하는 프로젝트를 하였고, 이후에는 인공위성 이미지로 cool roof를 식별하는 YOLO 모델을 만드는 프로젝트를 하였다.
"자동차 파손 여부 분류 모델이 어떻게 구분 되는 걸까"라는 생각으로 먼저 자동차 사진을 확인해보았다.


실습 자료로 제공된 Car.zip 파일을 colab에서 압축 해제하여 정상과 비정상을 각각 다른 폴더에 넣고난 후에 레이블을 1(파손)과 0(정상)으로 지정해줬다. 그 뒤에 두 파일을 합쳐서 데이터 셋으로 구성하였고 9:1 비율로 train셋과 test셋을 나눴다. CNN으로 모델을 구성하라는 지시 말고는 따로 정해진 것이 없어서 열심히 배운 내용을 바탕으로 이것저것 섞어서 모델을 구성하였다. 아래는 처음으로 작성한 모델 코드이다.

뭔가 성능을 더 잘 뽑아내고 싶은 마음으로 이것저것 찾아보고 최대한 많이 복잡하게 쌓아보자라고 생각하여서 이렇게도 해봤다.

이 모델로 학습 시킨 결과물은 이렇다... 가장 좋은 성능을 보인 epochs은 52였고 patience를 10으로 설정해서 더 이상 성능이 올라가지 않아서 62에서 끊겼다. 근데 정확도가 1에 가깝고 val_accuracy도 1이길래 이럴리가 있나 이상하다 싶어서 성능을 테스트 해봤다.

훈련에서는 1이라는 정확도가 나왔지만 validation 셋으로 성능을 평가했을 때는 정확도가 0.80이 나와서 아쉬운 마음이 많이 들었다. 다른 조원분들과 비교를 해봐도 다들 이 정도 근처로 다 나온 것 같다.

무엇을 맞췄고, 무엇을 못 맞췄는지가 궁금하여서 맞춘 사진, 못 맞춘 사진을 출력해봤다.

모델의 층을 마구잡이로 쌓아도 성능이 큰 차이가 없어서 다른 조원분들과 이야기를 나눴지만 다들 비슷하게 나와서 이거 데이터 양이 적어서 그런가보다. 라고 단정을 짓고 다음 미션인 사전 훈련된 모델로 훈련 및 예측 해보기를 진행했다.


내가 마구잡이로 층을 쌓아서 만든 모델이 사전 훈련된 모델보다 20배나 적은 파라미터를 가지고있다. 그 말은 사전훈련된 모델은 나보다 20배 더 마구잡이로 층을 쌓았다.. 데이터 양이 문제가 아니라 복잡한 모델이 더 학습을 잘하나?라는 생각과 함께 accuracy를 봤을 때 내 모델보다 낮게 나와서 별 차이 없으려나 싶었지만....

전지전능하신 사전 훈련된 모델은 4개 빼고 다 맞추셨다.. 정확도가 96으로 80이였던 내 모델을 가뿐히 즈려밟았다...

지난 딥러닝 시간 내내 층을 쌓는 방법, 층이 어떤 역할을 하는지 그리고 실습으로 익숙해져서 자신감이 붙은 상태로 미니 프로젝트를 시작했지만 사전훈련된 모델에 벽을 느끼며 생각했다. 내가 쌓을 필요 없이 훈련된 애를 가져오면 되겠구나.. 나는 왜 힘들게 하루종일 층을 쌓은 것인가... 생각을 했지만, 강사님이 우리가 실습한 것을 이해해야지 사전 훈련된 모델을 썼을 때 어떻게 작동하고 어떤 역할을 하는지 알 수 있기 때문에 필요한 과정이였다라고 설명을 해주셔서 어느정도 납득이 되었다.
다음으로 cool roof를 분류하는 프로젝트를 하게 되었다. 앞서 했던 프로젝트와 마찬가지로 데이터를 train과 valid 셋으로 나눴고, 사전 훈련된 yolov8s를 사용하여 객체탐지 + 분류를 하였다. yolov8과 같은 큰 딥러닝 모델을 앞선 프로젝트에서 사용해본 적이 없었다.. colab으로 실행해보았을 때 10분 넘게 걸린 모델을 다룬 것은 처음이였다. 그래서 모델이 실행되는 동안 조원분들과 이야기하는 시간이 많았따. 그 때 나온 말이 yolov8의 small, medium, large 등 가벼운 모델과 무거운 모델이 얼마나 차이나나 확인하자였고 이후에 서로 비교 해봤으나 생각보다 큰 차이가 없었다. cool roof가 흰색으로 칠해진 옥상을 말하는건데 데이터의 갯수가 적었고, 흐릿한 경우에는 내가 봐도 잘 모르겠어서 아마 컴퓨터도 분류가 힘들었겠구나 생각을 하였다. 아래는 그 결과이다.

그 후에 조원끼리 데이터 30장씩 모아다가 서로 공유를 하자라고 의견이 나와서 이미지를 30장 수집해서 roboflow를 사용해서 수동 라벨링을 한 후에 단톡방에 서로 공유를 하였다.


추가로 수집한 데이터를 추가해서 yolov8s 모델을 학습하였고, 전보다 훨씬 나은 성능이 나와서 아주 기뻤다. 훈련에 사용되는 데이터의 양이 많아야지 모델이 잘 분류한다는 사실을 한번 더 머리 속에 각인시킨 것 같다. 아래는 굉장한 성능을 보였던 나의 모델이다. 아주 이쁘게 분류를 잘했다 하하핳

이번 주도 마찬가지로 알고리즘 스터디를 진행하였다.
https://www.acmicpc.net/problem/18352
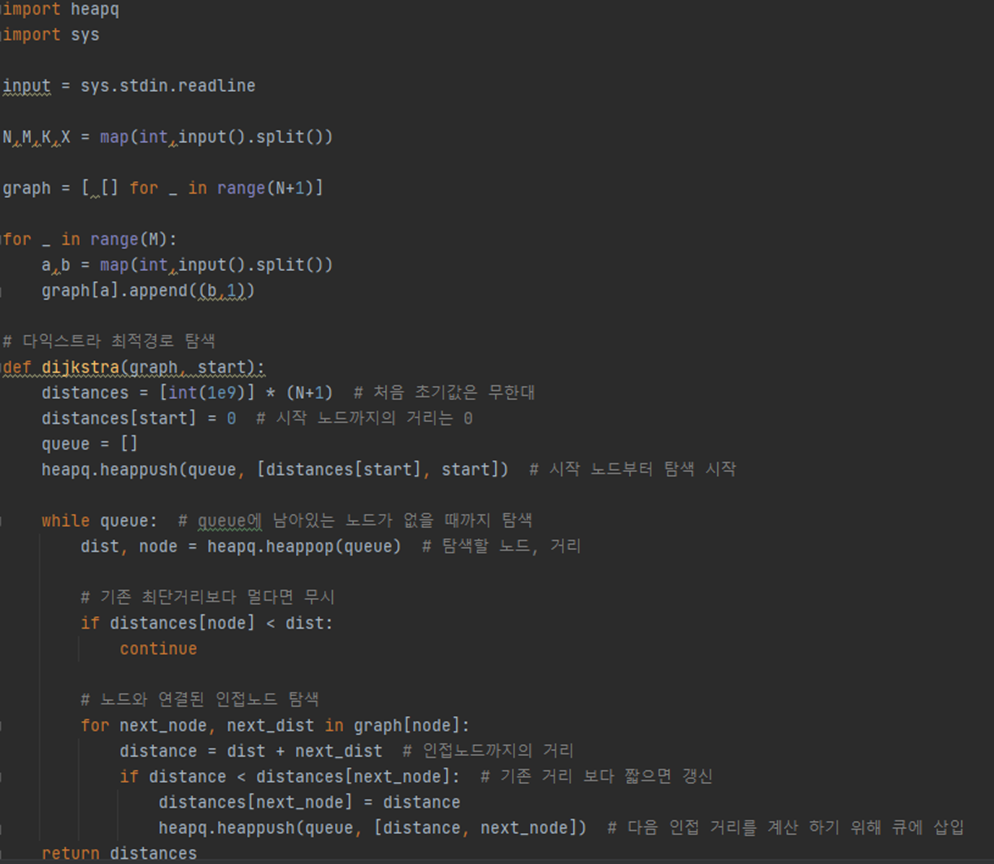
특정 거리의 도시 찾기 ( 실버 2) 문제를 다익스트라를 사용해서 풀었다. 아직 내 수준에는 안맞는 알고리즘인 것 같아서 어느정도 이해만하고 넘어가자라는 생각이 더 컸던 것 같다. 최근 점점 해이해져가는 내 모습을 보면서 초심을 찾아야겠다는 생각이 들었다..

으아아아아아 화이팅입니다 다들
'기자단 활동' 카테고리의 다른 글
| [KT 에이블스쿨 기자단] 10주차 회고 (0) | 2024.04.29 |
|---|---|
| [KT 에이블스쿨 기자단] 9주차 회고 (0) | 2024.04.29 |
| [KT 에이블스쿨 기자단] 7주차 회고 (0) | 2024.04.23 |
| [KT 에이블스쿨 기자단] 6주차 회고 (1) | 2024.04.19 |
| [KT 에이블스쿨 기자단] 5주차 회고 (1) | 2024.04.19 |



