
AI 전문가가 되고싶은 사람
(공부용) Rethinking the inception Architecture for computer vision 본문
(공부용) Rethinking the inception Architecture for computer vision
Kimseungwoo0407 2024. 9. 9. 19:20논문 링크 : https://arxiv.org/pdf/1512.00567v3
참고 사이트 :
K_03. Understanding of Inception
Inception 네트워크는 CNN 분류기 개발에서 중요한 이정표였습니다. 시작하기 전에(pun intended) 가장 인기 있는 CNN은 더 나은 성능을 얻기 위해 컨볼루션 레…
wikidocs.net
Review: Inception-v3 — 1st Runner Up (Image Classification) in ILSVRC 2015
In this story, Inception-v3 [1] is reviewed. By rethinking the inception architecture, computational efficiency and fewer parameters are…
sh-tsang.medium.com
서론
최근 몇 년 동안 딥러닝 합성 아키텍처의 구조적 개선 덕분에 분류 성능이 크게 향상되었다. 이러한 발전은 다양한 애플리케이션 도메인에서 시각적 특징을 보다 효과적으로 학습할 수 있게 해주며, 컴퓨티 비전 성능을 개선하는 데 기여하고있다.
● VGG와 GoogLeNet의 비교
VGG는 구조적으로 단순하면서도 높은 성능을 보이는 장점이 있지만, 그에 따라 높은 비용이 소요된다. 반면에 GoogLeNEt에서 사용된 Inception 아키텍처는 메모리와 계산 비용이 제한된 환경에서도 우수한 성능을 보여준다.
- GoogLeNet은 약 500만 개의 매개변수
- AlexNet은 약 6000만 개의 매개변수
- VGG는 AlexNet의 약 3배에 달하는 매개변수
● Inception 아키텍처의 장점
Inception의 계산 비용은 VGG나 다른 고성능 모델들에 비해 훨씬 낮은 계산 비용으로 성능을 유지할 수 있다. 이는 특히 대량의 데이터와 제한된 메모리 및 계산 자원을 가진 환경에서 유리하다. 물론, 다른 모델들을 특정 작업에 맞게 최적화하는 것도 가능하지만, 이 경우 복잡성이 증가할 수 있다. 따라서 Inception 아키텍처를 최적화하는 것이 실용적인 선택이 될 수 있다.
General Design Principles
합성곱 신경망을 사용한 다양한 아키텍처 선택에 대한 몇가지 설계 원칙을 설명한다. 아래 원칙의 유용성은 추측이며 정확성과 타당성 영역을 평가하기 위해 추가적인 실험적 증거가 필요하다. 하지만 이 원칙을 크게 벗어나면 품질 저하로 이어지는 경향이 있고, 편차가 감지될 경우 아키텍처를 수정 시 보통 성능이 개선된다.
1. Expressive BottleNeck 피하기
- 네트워크의 초기 단계에서 정보가 지나치게 압축되면 중요한 정보가 손실될 수 있다.
합성곱 신경망은 비순환 구조로써 입력 데이터를 처리하여 출력으로 변환한다. 네트워크의 초기 단계에서 정보가 지나치게 압축되면, 그 이후의 단계에서 중요한 정보가 충분히 전달되지 않을 수 있다. 이는 네트워크의 성능을 저하시킬 수 있는 중요한 원인 중 하나이다.
** 피드 포워드 네트워크는 정보가 한 방향으로만 흐르고, 순환이 없기에 초기 단계에서의 정보 손실이 회복되지 않는다.
2. 깊이와 폭의 균형을 유지하기
네트워크의 깊이(층 수)와 폭(각 층의 필터 수) 사이에 적절한 균형을 유지해야 한다.
네트워크의 깊이가 너무 깊으면 계산 비용이 증가하고, 너무 얕으면 표현력이 부족할 수 있다. 따라서, 깊이와 폭을 균형 있게 설계하여 네트워크가 충분한 표현력을 가지도록 해야한다.
3. 공간 집계 ( 입력 이미지의 공가넉 정보를 축소하거나 요약 )
3x3 합성곱을 적용하기 전에 입력의 차원을 줄이면 성능에 부정적인 영향을 주지 않는다. 이는 인접 단위 간의 강한 상관관계 덕분에 정보 손실이 적고, 차원 축소가 학습 속도를 빠르게 할 수 있음을 의미한다.
Factorizing Convolutions with Large Filter size
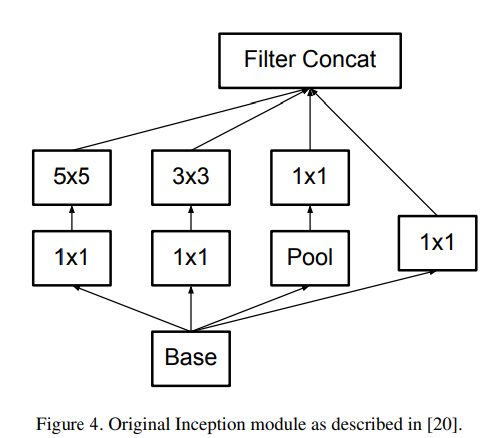
GoogLeNet에서 성능 향상 요인 : 차원 감소와 필터 분해
GoogLeNet의 성능 향상의 핵심 요소 중 하나는 효율적인 차원 감소이다. 이 아키텍처는 1x1 합성곱을 사용하여 채널 수를 줄이고 이후 3x3 합성곱을 적용하여 계산 비용을 절감한다.
1. 차원 감소와 계산 비용
- 1x1 합성곱: 채널 수를 줄여서 계산 비용을 낮추는 데 효과적이다.
- 3x3 합성곱: 차원 감소 후 적용하여 계산 비용을 줄일 수 있다.
2. 필터 분해의 장점
- 대형 필터의 문제: 큰 필터(예: 5x5, 7x7)는 계산 비용이 많이 들고, 활성화 간의 종속성을 포착하지만 계산량이 증가한다.
- 작은 필터의 대안: 큰 필터 대신 작은 필터(예: 3x3)를 두 번 사용하는 방법으로 비용을 줄일 수 있다. 예를 들어, 5x5 필터를 두 개의 3x3 필터로 분해함으로써 계산 비용을 비례적으로 절감할 수 있다.
5x5 필터를 3x3 2개로 교체

3. 비대칭 합성곱으로의 공간 분해
● 필터 크기와 효율성
3x3 이상의 필터는 계산량이 많고 비효율적일 수 있다. 대신, 비대칭 합성곱을 사용하면 계산 비용을 줄이면서도 비슷한 성능을 유지할 수 있다.
● 3x3 필터 대신 비대칭 합성곱
3x3 필터 : 일반적으로 공간 집계에서 효과적이지만, 계산 비용이 높다.
3x1 및 1x3 조합 : 3x3 필터와 같은 성능을 내면서도 계산량이 감소한다.
● 레이어에 따른 필터 선택
초기 레이어 : 작은 필터(3x3)가 더 효과적일 수 있다. 이는 작은 필터가 중요한 세부 정보를 포착하는 데 유리하기 때문이다.
중간 레이어 : 1x7과 7x1 조합의 비대칭 필터가 더 좋은 성능을 보인다. 중간 크기 피처 맵에서 비대칭 필터는 더 많은 정보를 효과적으로 처리할 수 있다.


Utility of Auxiliary Classifiers
● GoogLeNet의 보조 분류기

1. 보조 분류기의 도입과 목적
GoogLeNet은 깊은 네트워크의 수렴을 개선하기 위해 보조 분류기를 도입했다. 보조 분류기의 주요 목적은 하위 계층으로 유용한 그래디언트를 전달하여 그래디언트 소실 문제를 완화하고 학습 과정에서 수렴을 개선하는 것이었다.
2. 초기 학습의 효과
보조 분류기가 학습 초기에 수렴을 개선하지 못하는 것으로 발견하였다. 즉, 보조 분류기의 유무에 관계없이 두 모델의 성능은 높은 정확도에 도달하기 전까지 거의 동일했다.
3. 학습 종료 시점의 개선
학습이 종료되었을 때, 보조 분류기가 있는 네트워크가 더 높은 정확도를 보였다. 이는 보조 분류기가 초기 학습 단계에서는 큰 영향을 미치지 않지만, 학습이 진행됨에 따라 네트워크의 성능을 향상시키는 데 기여한다는 것을 알 수 있다.
4. 정규화 역할
보조 분류기가 저수준 피처를 개선한다는 가설이 잘못되었을 가능성을 제기하였다. 대신 보조 분류기가 네트워크의 정규화 역할을 한다는 새로운 가설이 제기되었다. 보조 분류기는 주 분류기가 더 잘 학습하도록 돕고, 배치 정규화나 드롭아웃 계층과 함께 사용할 때 성능을 더욱 향상시킬 수 있다.
Efficient Grid Size Reduction
1. 전통적인 방법의 한계
전통적으로 합성곱과 풀링 계층을 사용하여 특성 맵의 크기를 줄여왔다. 그러나 이러한 방법은 반복할수록 계산 비용이 증가하게 된다. 특히, 풀링 연산은 중요한 정보를 손실할 수 있으며, 계산 효율성 또한 제한적일 수 있다.
2. 대안으로서의 합성곱
2x2 풀링을 대체하여 2x2 합성곱을 사용할 수 있지만, 이 경우 위에서 언급한 네트워크의 병목 현상이 발생할 수 있다. 즉, 네트워크가 중요한 정보를 놓칠 수 있으며, 성능에 부정적인 영향을 미칠 수 있다.
3. 병렬 스트라이드 2 블록
이러한 문제를 해결하기 위해 병렬 스트라이드 2 블록을 사용하는 방법이 도입되었다. 이 방법은 두 개의 병렬 블록을 사용하여 그리드 크기를 줄이는 방식이다.
- P 블록 (풀링 계층): 표준 풀링 연산을 사용하여 입력의 공간적 크기를 줄인다.
- C 블록 (스트라이드 2 합성곱 계층): 스트라이드 2를 가진 합성곱 연산을 사용하여 특성 맵의 크기를 줄인다.
4. 병렬 스트라이드 2 블록의 장점
이 접근 방식은 계산 비용을 줄이면서도 중요한 정보를 더 잘 유지할 수 있도록 설계되었다. 풀링과 합성곱을 병렬로 활용함으로써, 네트워크는 정보 손실을 최소화하면서도 그리드 크기를 효과적으로 줄일 수 있다.

Inception-v3 아키텍처 및 Label Smoothing

총 42개의 레이어를 사용하여 계산 비용이 GoogLeNet보다 약 2.5배 높고 VGGNet보다 훨씬 효율적이다.
● Label Smoothing
Label Smoothing은 특정 레이블에 과도한 확산을 방지하고 모든 레이블에 대해 긍정적인 확률 할당을 유도한다. 이는 모델의 성능을 향상시키고 일반화 능력을 높여준다.
ex) 정답 레이블의 확률이 1-E로 설정되고, 나머지 레이블의 확률은 균등하게 E / (K-1)로 설정된다. E는 Smoothing parameter이고, K는 클래스의 총 수이다.
결론

Inception-v1 : 29%
Inception-v2 : 25.2%
Inception-v3 : 23.4%
+ RMSProp : 23.1%
+ Label Smoothing : 22.8%
+ 7x7 Factorization : 21.6% -> 3개의 3x3 변환 계층으로 분해하는 것
+ Auxiliary Classifier : 21.2%
● Inception-v3 모델의 성능과 ILSVRC 2015 대회에서의 결과
1. 다중 모델 및 다중 크롭
Inception-v3 모델을 여러 개의 모델로 앙상블하고, 각각의 모델에서 다양한 크롭을 사용하여 성능을 향상시켰다.
다중 크롭은 이미지에서 여러 위치와 크기로 자른 샘플을 사용하여 예측하는 기법이다.
Inception-v3는 ILSVRC 2015 대회에서 2위를 차지했다. 1등은 ResNet이 차지하였다고한다.

'논문' 카테고리의 다른 글
| (공부용) Deep Residual Learning for Image Recognition (4) | 2024.09.11 |
|---|---|
| (구현) Rethinking the inception Architecture for computer vision (0) | 2024.09.10 |
| (구현) VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION (0) | 2024.09.09 |
| (공부용) VERY DEEP CONVOLUTIONAL NETWORKSFOR LARGE-SCALE IMAGE RECOGNITION (2) | 2024.09.07 |
| (구현) Going deeper with convolutions (3) | 2024.09.06 |

