
AI 전문가가 되고싶은 사람
(공부용) Deep Residual Learning for Image Recognition 본문
논문 링크 : https://arxiv.org/pdf/1512.03385v1
참고 사이트 :
Review: ResNet — Winner of ILSVRC 2015 (Image Classification, Localization, Detection)
In this story, ResNet [1] is reviewed. ResNet can have a very deep network of up to 152 layers by learning the residual representation…
towardsdatascience.com
https://www.youtube.com/watch?v=Fypk0ec32BU&t=3s
서론
최근 CNN은 이미지 분류와 같은 시각적 인식 작업에서 획기적인 성과를 이루어내고 있다. 이러한 성공은 딥 네트워크가 다양한 수준의 피처를 자연스럽게 통합하며, 저수준, 중수준, 고수준의 피처를 엔드투엔드 방식으로 학습할 수 있기 때문이다. 이때 네트워크의 깊이는 매우 중요한 요소로 작용하며, 레이어가 많아질수록 네트워크는 더욱 복잡한 피처를 학습할 수 있다. 특히 ImageNet과 같은 대규모 데이터 세트에서 가장 좋은 성과를 낸 모델들은 16~30개의 레이어를 가진 매우 깊은 네트워크였다.
그러나 네트워크의 깊이를 증가시키는 것은 생각보다 단순한 일이 아니다. 더 많은 레이어를 쌓는 것이 더 나은 성능을 보장하는 것이 아니기 때문이다. 실제로 네트워크 깊이가 증가하면 소실/폭발 그래디언트 문제라는 장애물이 나타난다. 이는 역전파 알고리즘이 초기에 수렴하는 것을 방해하여 학습이 불안정해지는 문제다. 다행히 이 문제는 정규화된 초기화 방법과 중간에 추가되는 정규화 레이어를 통해 어느 정도 해결되었다.

하지만 깊은 네트워크에서 또 다른 문제가 발생하였다. 위의 그래프와 같이 네트워크의 깊이가 증가할수록 학습 정확도가 더 나빠지거나, 성능이 포화 상태에 이르는 저하 문제가 발생하는 것이다. 이는 과적합 문제와는 다르며, 오히려 레이어가 너무 많아져 학습이 어려워지는 현상으로 볼 수 있다. 즉, 더 많은 레이어를 무작정 추가한다고 해서 반드시 성능이 향상되지 않으며, 오히려 더 높은 학습 오류를 초래하는 경우도 있다.
이 논문에서는 이러한 문제를 해결하기 위해 잔여 학습(Residual Learning) 프레임워크를 제안한다. 잔여 학습은 레이어가 직접 목표 매핑에 맞추기보다 잔여 매핑에 맞추도록 하여, 네트워크의 최적화를 쉽게 만듭니다. 이를 통해 더 깊은 네트워크도 안정적으로 학습할 수 있으며, ImageNet과 같은 데이터 세트에서 우수한 성능을 달성했다. 우리의 152개의 레이어 잔여 네트워크는 복잡성을 줄이면서도 기존 네트워크보다 뛰어난 결과를 보였다.

해당 논문에서 언급한 skip connection은 딥러닝에서 자주 발생하는 그래디언트 소실 및 폭발 문제를 해결하는 데 중요한 기술이다. 이 문제는 네트워크가 깊어질수록 역전파 과정에서 그래디언트 값이 매우 작아지거나 커져 학습이 불안정해지거나 멈추는 현상이다. ResNet은 이러한 문제를 해결하기 위해 skip connection을 도입했다. 이 기술은 네트워크에서 몇 개의 레이어를 거친 후, 입력값 x를 해당 레이어들의 출력값에 더해주는 방식이다.
이렇게 함으로써 그래디언트 소실 문제를 완화시킬 수 있다.. 간단히 말해, 그래디언트가 매우 작아져도 입력값을 더해줌으로써 그래디언트를 안정화시킬 수 있다.
기본 매핑(H(x)): 네트워크가 학습하려는 목표 매핑.
잔여 매핑(F(x)): skip connection에서는 목표 매핑을 직접 학습하는 대신, 잔여 값 F(x)=H(x)−x를 학습한다. 레이어들은 F(x)라는 잔여 값을 학습한 후, 이를 입력 x에 더하여 최종 출력 H(x) = F(x) + x를 생성한다.
Deep Residual Learning
● Residual Learning (잔여 학습)
딥러닝 모델이 깊어질수록, 각 레이어는 점차 복잡한 함수를 학습하게 된다. 잔여 학습은 네트워크가 목표 함수 H(x)를 직접 학습하는 대신, 목표 함수와 입력 값의 차이인 잔여 값 F(x)를 학습하게 함으로써, 학습을 더 쉽게 만든다.
잔여 학습의 장점은 항등 매핑을 직접 학습하는 대신, 항등 매핑에서 벗어난 잔여 값만을 학습하도록 만들어준다. 만약 항등 매핑이 최적이라면, 잔여 학습은 이 값을 0에 가깝게 만들어 항등 매핑에 가까워질 수 있다.
항등 매핑이 최적의 솔루션일 가능성은 낮지만, 잔여 학습을 통해 네트워크는 항등 매핑을 기준으로 학습할 수 있다. 이는 잔여 매핑을 학습하는 것이 목표 매핑을 직접 학습 하는 것보다 쉬울 수 있다는 아이디어에 기반을 한다. 실험 결과, 잔여 함수가 대부분 작은 값을 가진다는 사실이 밝혀졌고, 이는 항등 매핑이 학습의 기준이 될 수 있다는 것을 보여준다.
● ResNet Architecture

34-layer plain 아키텍처 : VGG 네트워크의 설계를 바탕으로 한 일반 네트워크
34-layer residual 아키텍처 : 일반 네트워크를 기반으로 skip connection을 추가한 잔여 네트워크
실험 결과
Imagenet 데이터셋에서 일반 네트워크와 잔여 네트워크의 성능 평가 결과는 아래와 같다.

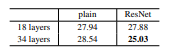
일반 네트워크를 사용하는 경우 그래디언트 문제로 인해 18개의 레이어가 34개 레이어보다 성능이 좋다.
Resnet을 사용하는 경우 34개의 레이어가 18개의 레이어보다 뛰어나기 때문에 skip connection으로 그래디언트 문제가 해결된 것을 알 수 있다.
또한 18개의 레이어에서 일반 네트워크와 Resnet의 성능 차이가 많이 나타나지 않는데 이는 얕은 네트워크에서는 그래디언트 문제가 나타나지 않기 때문이다.
● ILSVRC

ResNet-34 A,B,C를 봤을 때 C > B > A 인 것을 알 수 있는데 이는 점차 추가 매개변수를 도입하여 성능을 개선했지만 큰 차이가 없었다. 하지만 깊이를 152층까지 늘렸을 때 오류율이 5.71을 얻었으며, 이는 VGG-16, GoogLeNet, PReLU-net보다 훨씬 우수한 것을 알 수 있다.


두 실험에서도 ResNet-152가 가장 낮은 오류율을 달성하였다.

● CIFAR-10

skip connection을 사용하면 1202까지도 최적화 어려움이 없어 수렴할 수 있다. 하지만 1202 층을 쌓았을 때 110층보다 오류율이 더 증가하는 것을 알 수 있다. 이는 논문의 미해결 문제로 남아있다고 한다.
결론
Residual Learning 프레임워크가 매우 깊은 신경망을 효과적으로 훈련할 수 있도록 돕는다!
깊이가 증가함에 따라 학습이 어려워지는 문제를 해결해주고, 더 깊은 네트워크에서도 효과적으로 최적화할 수 있게한다.
또한 다른 모델과 비교했을 때 매우 낮은 오류율을 기록하였고, ILSVRC 2015 분류 대회에서 1위를 차지하는 성과를 이뤘다.
Residual Learning은 다양한 비전 및 비전 외 문제에도 적용이 가능하며 다른 인식 작업에서도 우수한 일반화 성능을 보여준다. 이는 COCO와 같은 여러 대회에서의 1위 수상으로 입증되었다.
'논문' 카테고리의 다른 글
| Transformer 리뷰를 위한 공부(완료) (1) | 2024.11.18 |
|---|---|
| (구현) Deep Residual Learning for Image Recognition (0) | 2024.09.12 |
| (구현) Rethinking the inception Architecture for computer vision (0) | 2024.09.10 |
| (공부용) Rethinking the inception Architecture for computer vision (2) | 2024.09.09 |
| (구현) VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION (0) | 2024.09.09 |

