
AI 전문가가 되고싶은 사람
파이썬 시각화와 단변량 분석 복습 ( + 시계열 데이터 처리 ) 본문
● 시계열 데이터 처리
1. 라이브러리 및 데이터 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sales = pd.read_csv("https://raw.githubusercontent.com/DA4BAM/dataset/master/ts_sales_simple.csv")
products = pd.read_csv("https://raw.githubusercontent.com/DA4BAM/dataset/master/ts_product_master.csv")data.head()
2. 날짜 타입으로 변환
- pd.to_datetime(날짜데이터, format = ' 입력되는 날짜 형식 ')
data['Date'] = pd.to_datetime(data['Date'])
# date = pd.to_datetime(data, format = '%Y-%m-%d') # 연도-월-일
3. 날짜 요소 추출
# 연도
date.dt.year# 월
date.dt.month# 일
date.dt.day# 요일 ( 0 - 월 , 6 - 일 )
date.dt.weekday# 요일 이름
date.dt.day_name()
4. 시간에 따른 흐름 추가하기
- shift : 시계열 데이터에서 시간의 흐름 전후로 이동시킬 때 사용
temp = data.loc[:,['Date','Amt']]# 전날 매출액 열을 추가합시다.
temp['Amt_lag'] = temp['Amt'].shift() #default = 1
# 전전전날 매출액 열을 추가.
temp['Amt_lag2'] = temp['Amt'].shift(3) # 3행 shift
# 다다음날 매출액 열을 추가합시다.
temp['Amt_lag_1'] = temp['Amt'].shift(-2)
temp.head()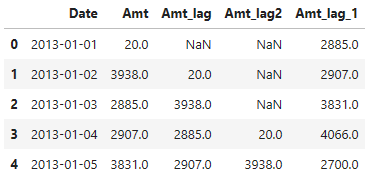
- rolling + 집계함수 : 시간의 흐름에 따라 일정 기간 동안 평균을 이동하면서 구하기
* rolling(n, min_periods ) : n = 일정기간 , min_periods = 최소 데이터 수
# 5일 이동평균 매출액을 구해 봅시다.
temp['Amt_MA7_1'] = temp['Amt'].rolling(5).mean()
temp['Amt_MA7_2'] = temp['Amt'].rolling(5, min_periods = 1).mean()
temp.head(10)
- diff : 특정 시점 데이터, 이전시점 데이터와의 차이 구하기
# 5일 이동평균 매출액을 구해 봅시다.
temp['Amt_D1'] = temp['Amt'].diff() # default 1
temp['Amt_D2'] = temp['Amt'].diff(5)
temp.head(10)
● 시각화 라이브러리
1. 환경 준비
import pandas as pd
import numpy as np
# 시각화 라이브러리
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv('https://raw.githubusercontent.com/DA4BAM/dataset/master/airquality_simple2.csv')
data['Date'] = pd.to_datetime(data['Date'])
data.dropna(axis = 0, inplace = True)
data.head()

2. 기본 차트 그리기
- plt.plot(1차원 값) : 라인 차트
# x축 인덱스 y축 1차원 값
plt.plot(data['Date'], data['Wind'])
plt.show()
3. 차트 꾸미기
plt.plot(data['Date'], data['Wind'])
plt.xticks(rotation = 45) # x축 값 꾸미기 : 방향을 30도 틀어서
plt.xlabel('Date') # x축 이름 지정
plt.ylabel('Wind') # y축 이름 지정
plt.title('Daily Airquality') # 타이틀
plt.show()
- 라인 스타일 조정
color 및 marker의 지정 값들은 아래에 있는 사이트와 표를 참고해서 사용하면 됨
List of named colors — Matplotlib 3.8.3 documentation
List of named colors — Matplotlib 3.8.3 documentation
List of named colors This plots a list of the named colors supported by Matplotlib. For more information on colors in matplotlib see Helper Function for Plotting First we define a helper function for making a table of colors, then we use it on some common
matplotlib.org

plt.plot(data['Date'], data['Wind']
,color='red' # 칼러
, linestyle='solid' # 라인스타일
, marker='o') # 값 마커(모양)
plt.xlabel('Date')
plt.ylabel('Wind')
plt.title('Daily Airquality')
plt.xticks(rotation=45)
plt.show()
- 여러 그래프 겹쳐서 그리기
# 첫번째 그래프
plt.plot(data['Date'], data['Wind'], color='green', linestyle='dotted', marker='o', label = 'Wind')
# 두번째 그래프
plt.plot(data['Date'], data['Temp'], color='r', linestyle='-', marker='s', label = 'Temp')
plt.xlabel('Date')
plt.ylabel('Wind')
plt.title('Daily Airquality')
plt.xticks(rotation=45)
plt.legend(loc = 'upper right') # 레이블 표시하기. loc = : 위치
plt.grid()
# 위 그래프와 설정 한꺼번에 보여주기
plt.show()

- 1행 3열 그래프 그리기
plt.figure(figsize = (15,5))
plt.subplot(1,3,1)
plt.plot('Date', 'Temp', data = data)
plt.xticks(rotation = 40)
plt.grid()
plt.subplot(1,3,2)
plt.plot('Date', 'Wind', data = data)
plt.xticks(rotation = 40)
plt.subplot(1,3,3)
plt.plot('Date', 'Ozone', data = data)
plt.xticks(rotation = 40)
plt.grid()
plt.ylabel('Ozone')
plt.tight_layout() # 그래프간 간격을 적절히 맞추기
plt.show()
● 단변량 분석_수치형변수
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/titanic_simple.csv'
titanic = pd.read_csv(path)
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/air2.csv'
air = pd.read_csv(path)
1. 값들의 기술적 통계 확인
count : 데이터의 총 개수
mean : 데이터 리스트의 평균
std : 표준분산 , min : 최소값, quantile, mode : 최빈값 등
titanic['Fare'].describe()
# 데이터프레임의 전체 변수들 기초통계량 조회
titanic.describe(include='all')
2. 히스토그램
plt.hist(titanic.Fare, bins = 5, edgecolor = 'gray')
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.show()
3. 밀도함수 그래프 (kde plot)
- 히스토그램의 단점 : 구간의 너비를 어떻게 잡는지에 따라 전혀 다른 모양이 될 수 있음
- 밀도함수 그래프 : 막대의 너비 가정 x 모든 점에서 데이터의 밀도를 추정하는 커널 밀도 추청 방식을 사용하여 단점 해결
- 밀도함수 그래프 아래 면적은 1
sns.kdeplot(titanic['Fare'])
# sns.kdeplot(x='Fare', data = titanic)
plt.show()
4. boxplot
- 주의!! 값에 nan 값이 있으면 그래프가 그려지지 않음
but seaborn 패키지 함수들은 nan 값을 알아서 빼줌 -> sns.boxplot을 쓰자~
# titanic['Age']에는 NaN이 있습니다. 이를 제외한 데이터
temp = titanic.loc[titanic['Age'].notnull()]
plt.boxplot(temp['Age']) # vert = False 할 경우 옆으로 그림
plt.grid()
plt.show()
sns.boxplot(x = titanic['Age'])
plt.grid()
plt.show()
● 단변량 분석_범주형변수
1. 환경 준비
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/titanic_simple.csv'
titanic = pd.read_csv(path)
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/air2.csv'
air = pd.read_csv(path)
2. 범주형 변수
- 범주별 빈도수 : value_counts()
titanic['Sex'].value_counts()
- 범주별 비율 : value_counts(normalize = True)
titanic['Sex'].value_counts(normalize = True)
3. 시각화
- bar chart
sns.countplot(x = 'Sex', data = titanic)
plt.grid()
plt.show()
- pie chart
temp = titanic['Sex'].value_counts()
plt.pie(temp.values, labels = temp.index, autopct = '%.2f%%')
plt.show()
'기자단 활동' 카테고리의 다른 글
| 분산 분석 ( ANOVA) 및 이변량 분석 복습 (0) | 2024.03.01 |
|---|---|
| 가설 검정, 중심 극한 정리, t-test 정리 및 복습 (2) | 2024.02.28 |
| 파이썬 프로그래밍 ( 데이터 프레임 변경 및 결합 ) 복습 (1) | 2024.02.26 |
| 파이썬 프로그래밍 (pandas) 복습 (0) | 2024.02.24 |
| 파이썬 프로그래밍 ( Numpy ) 복습 (0) | 2024.02.23 |



