
AI 전문가가 되고싶은 사람
Word2vec 본문
https://seungwoo0407.tistory.com/62
Transformer 리뷰를 위한 공부
신경망과 시퀀스 모델 학습Transformer의 등장 배경인 RNN 계열 모델과 Attention 메커니즘을 이해합니다.필수 학습 주제RNN (Recurrent Neural Networks): 순차 데이터 처리 기초https://seungwoo0407.tistory.com/63 RNN(R
seungwoo0407.tistory.com
Seq2Seq (Sequence-to-Sequence) 모델을 공부하기 전 Word2vec 개념을 알아야한다고 해서 먼저 공부하도록 하겠습니다.
https://www.youtube.com/watch?v=pC6P-rBrwms
신박 Ai님 설명을 너무 잘해주셔서 마찬가지로 해당 영상으로 공부하였습니다.
단어 임베딩의 필요성

원-핫 인코딩의 문제점은 단어 간 관계를 표현하지 못하는 것과 차원이 커짐으로써 계산 효율이 떨어진다는 것이다.
예를 들어, cat과 dog은 유사한 단어이지만, 원-핫 벡터는 서로 완전히 직교하여 관계를 반영하지 못한다. 또한 단어 집합의 크기가 10,000개라면 각 단어는 10,000차원의 벡터로 표현되기 때문에 메모리 소모가 크고 계산 효율이 떨어지며, 큰 규모의 텍스트 데이터를 다룰 때는 비효율적이다.
대안: 단어 임베딩
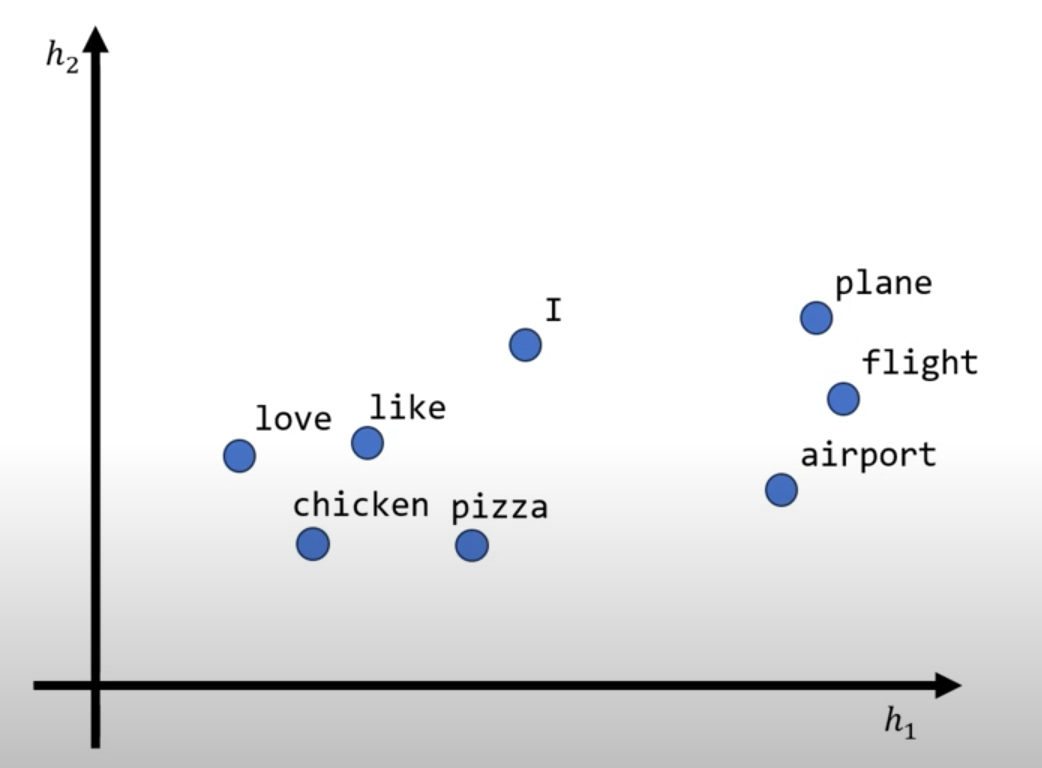
Word2Vec는 단어를 고정된 크기의 저차원 실수 벡터로 변환하여 단어 간의 문맥적 의미를 반영한다.
예를 들어, "king" - "man" + "woman" ≈ "queen"이라는 벡터 연산이 가능하며, 이는 단어 간 의미적 유사성을 벡터 연산으로 표현할 수 있음을 보여준다. 이 방식은 원-핫 인코딩과 달리 의미적으로 유사한 단어들을 공간적으로 가까이 배치하여 성능을 향상시킨다.
CBOW (Continuous Bag of Words)와 Skip-gram

CBOW는 주변 맥락 단어들의 정보를 바탕으로 중심 단어를 예측하는 모델이다. 맥락 단어들의 벡터를 평균으로 결합하여 해당 평균값을 이용해 중심 단어를 예측하는 방식으로 동작한다. 여러 맥락 단어의 정보를 한 번에 처리하여 하나의 단어를 예측하기에, 훈련 속도가 빠르고 효율적으로 학습이 가능하다.
Skip-gram은 중심 단어가 주어졌을 때, 해당 단어를 중심으로 한 주변 맥락 단어들을 예측하는 모델이다. 타겟 단어를 입력으로 받아 각 맥락 단어를 하나씩 예측하는 방식으로 동작한다. 이 모델은 작은 데이터 세트에서도 우수한 성능을 보이고, 단어 간의 더 복잡하고 미묘한 관계를 효과적으로 학습할 수 있다.
Word2vec의 한계
Word2vec은 단어를 고정된 벡터로 표현하기 때문에 문맥에 따른 단어의 다양한 의미를 반영하지 못하는 한계가 있다. 예를 들어, 'bank'라는 단어는 문장에 따라 '강둑'을 의미할 수도 있고, '금융기관'을 의미할 수도 있지만, Word2Vec에서는 이러한 차이를 고려하지 않고 단 하나의 벡터로 'bank'를 표현한다. 이러한 한계를 극복하기 위해 BERT, GPT와 같은 문맥적 임베딩 기법이 등장했다. 문맥적 임베딩은 단어가 문장에서 사용된 위치와 주변 문맥을 기반으로 벡터를 동적으로 생성하기에 같은 단어라도 문맥에 따라 서로 다른 벡터로 표현할 수 있다. 즉 다의어의 의미 차이를 효과적으로 반영할 수 있다.
이러한 특성 덕분에 문맥적 임베딩은 자연어 처리 작업에서 더 높은 정확도와 표현력을 제공한다고 한다.
마무리
Word2Vec은 단어를 저차원 실수 벡터로 변환하여 단어 간의 문맥적 관계를 벡터 공간에 반영하고, 기존의 원-핫 인코딩 방식보다 계산 효율성을 크게 높였다. 이러한 특성 덕분에 단어 간의 유사성을 수치적으로 나타내거나, 단어 벡터 간의 연산을 통해 의미 관계를 분석할 수 있게 되었다. 하지만 Word2Vec은 각 단어를 고정된 벡터로 표현하기 때문에 문맥에 따라 달라지는 단어의 다양한 의미를 반영하지 못하는 한계가 존재합니다. 이를 극복하기 위해 BERT와 GPT와 같은 문맥적 임베딩(Contextual Embedding) 기법이 개발되었다.
'논문' 카테고리의 다른 글
| Seq2seq+Attention (1) | 2024.11.25 |
|---|---|
| Seq2seq (0) | 2024.11.25 |
| LSTM(Long Short-Term Memory) + GRU (1) | 2024.11.19 |
| RNN(Recurrent Neural Networks) (0) | 2024.11.18 |
| Transformer 리뷰를 위한 공부(완료) (1) | 2024.11.18 |



