
AI 전문가가 되고싶은 사람
Seq2seq+Attention 본문
https://www.youtube.com/watch?v=cu8ysaaNAh0
Attention 매커니즘

Seq2Seq 모델은 인코더와 디코더로 구성되어 입력 시퀀스를 압축된 벡터로 변환한 후, 이를 바탕으로 출력 시퀀스를 생성하는 구조이다. 하지만 입력 시퀀스가 길어질 경우, 컨텍스트 벡터에 모든 정보를 담기 어려운 한계가 있다. 이를 해결하기 위해 Attention 매커니즘이 도입되었다.

Attention 매커니즘은 디코더가 출력 시퀀스의 각 단어를 생성할 때 입력 시퀀스의 중요한 부분을 강조하도록 설계되었다. 이를 통해 모델은 더 긴 시퀀스를 처리할 수 있고, 번역 품질 향상과 복잡한 문장 구조 처리에 강점을 보인다.
Attention 작동 방식

Attention 매커니즘의 작동 방식은 다음과 같다.
먼저 입력 시퀀스의 각 단어에 대한 은닉 상태를 저장하고, 그런 다음 seq2seq때와 마찬가지로 context vector를 만들고 디코더에 넣어서, 디코더의 은닉 상태와 출력 값을 구한다.

디코더의 현재 은닉 상태와 관련 있는 입력 시퀀스의 은닉 상태 간의 유사성을 계산한다. 이 과정에서 두 벡터의 Dot product(내적)를 사용해 Attention score를 구한다.

이후 소프트맥스를 통해 이 스코어를 확률 분포로 변환하여 정규화하고, 각 어텐션 스코어를 입력 시퀀스의 은닉 상태에 가중치로 곱한다.
* 소프트맥스의 역할
Attention score를 소프트맥스를 통해 확률 분포로 변환하는 과정으로 입력 시퀀스의 각 단어에 할당된 중요도를 0~1 사이 값으로 정규화하며, 합이 1이 되도록 만들어 해석이 더 직관적으로 가능하게 만든다.

이를 합산하여 새로운 Context vector를 생성하고, 이를 디코더의 다음 은닉 상태 계산에 사용한다.
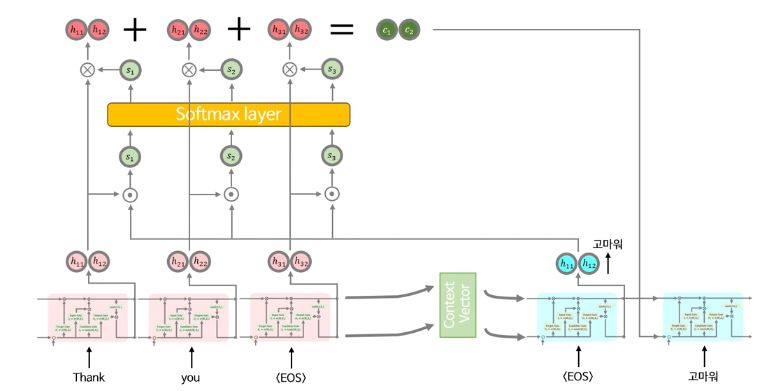
어텐션 메커니즘은 입력 시퀀스의 각 요소에 대한 가중치를 조정함으로써 출력 시퀀스의 품질을 향상시키고, 모델이 더 긴 문맥을 효과적으로 처리할 수 있도록 돕는다.
Attention 장점 및 단점
Attention 매커니즘의 장점으로는 먼저, 입력 시퀀스에서 멀리 떨어진 단어 간의 관계를 효과적으로 파악할 수 있어 장거리 의존성 처리가 가능하다는 점이 있다. 또한, 기존 Seq2Seq 모델에서 발생하던 Context vector의 정보 압축 문제를 해결하여 정보 손실을 최소화하며, 모든 입력의 히든 상태를 사용해 더 풍부한 정보를 디코더로 전달할 수 있다. Attention 매커니즘은 다양한 길이의 입력 시퀀스를 유연하게 처리할 수 있으며, 중요한 단어에만 집중해 모델의 효율성을 높이는 장점도 있다. 어텐션 맵을 활용해 어떤 입력 단어가 디코더 출력에 영향을 미쳤는지 시각화할 수 있어 결과의 해석 가능성이 높아지고, 기계 번역, 요약, 질문 응답, 이미지 처리, 음성 인식 등 다양한 분야에 응용 가능하다는 점도 큰 강점이다. 특히 트랜스포머 구조에서는 병렬 처리를 지원해 학습 속도를 크게 향상시키는 이점이 있다.
반면 단점으로는 계산 비용이 높다는 문제가 있다. Attention 메커니즘은 모든 입력-출력 쌍의 유사도를 계산하기 때문에 시퀀스 길이가 길어질수록 계산량이 급격히 증가하며, 긴 문장이나 대규모 데이터 처리 시 성능 저하로 이어질 수 있다. 입력 길이가 길어질수록 어텐션 가중치 행렬의 크기가 커져 메모리 요구량도 증가하며, 이는 특히 GPU 메모리의 한계로 연결될 수 있다. 매우 긴 시퀀스에서는 장거리 의존성의 약점이 드러나 정보 손실이나 성능 저하가 발생할 수 있으며, 이를 해결하기 위해 Longformer나 Reformer 같은 확장 모델이 필요하다. 또한, RNN이나 LSTM 모델에 비해 구현과 설계가 복잡해 다양한 점수 계산 방식과 하이퍼파라미터 설정이 요구된다. 실시간 애플리케이션에서는 계산량이 속도 병목으로 작용할 수 있으며, 매우 긴 시퀀스를 처리하거나 대규모 데이터에서 성능을 높이기 위해 Sparse Attention 같은 추가적인 기법을 적용해야 하는 확장성 문제도 존재한다.
'논문' 카테고리의 다른 글
| RNN 구현 (2) | 2024.12.06 |
|---|---|
| Transformer (2) | 2024.12.04 |
| Seq2seq (0) | 2024.11.25 |
| Word2vec (1) | 2024.11.20 |
| LSTM(Long Short-Term Memory) + GRU (1) | 2024.11.19 |



