
AI 전문가가 되고싶은 사람
BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding 본문
BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding
Kimseungwoo0407 2024. 12. 26. 19:18Introduction
최근 자연어 처리(NLP) 분야는 언어 모델의 사전 훈련(pre-training)을 통해 크게 발전하고 있다. 특히 BERT(Bidirectional Encoder Representations from Transformers)는 기존 모델의 한계를 극복하며 다양한 작업에서 뛰어난 성능을 보여주어 NLP의 새로운 패러다임을 제시했다.
최근 연구들은 사전 훈련된 언어 모델이 NLP 작업의 성능을 획기적으로 향상시킬 수 있음을 입증했다. 예를 들어, Dai와 Le(2015)는 RNN을 활용한 사전 훈련 모델을 제안했고, Peters et al.(2018)은 ELMo를 통해 문맥 기반 임베딩을 구현했다. 또한 Radford et al.(2018)의 GPT와 Howard와 Ruder(2018)의 ULMFiT 모델도 이 같은 발전을 보여주었다. 이들은 사전 훈련 모델이 분류, 질문 응답 등 다양한 NLP 작업에 효과적임을 증명했다.
NLP 작업은 크게 문장 수준 작업과 토큰 수준 작업으로 나눌 수 있다. 문장 수준 작업에는 자연어 추론(NLI)이나 패러프레이징과 같이 문장을 전체적으로 분석해 관계를 예측하는 작업이 포함된다. 반면, 토큰 수준 작업은 개체명 인식(NER)이나 질문 응답(QA)처럼 세부적인 출력이 요구되는 작업을 포함한다.
하지만 기존 언어 모델에는 명확한 한계가 존재했다. 대부분 단방향(왼쪽에서 오른쪽)으로 문맥을 처리하는 구조로 설계되었기 때문에 문장 수준 작업에서는 비효율적일 수 있었으며, 특히 토큰 수준 작업에서는 문맥을 양방향으로 모두 고려할 필요가 있었다. 예를 들어, OpenAI의 GPT는 단방향 모델로, 이러한 한계로 인해 복잡한 작업에서 최적의 성능을 발휘하기 어려웠다.
이러한 문제를 해결하기 위해 BERT는 혁신적인 방식을 제안했다. BERT는 마스크드 언어 모델(Masked Language Model)을 활용해 일부 입력 토큰을 마스킹하고, 모델이 이 마스킹된 토큰의 원래 값을 예측하도록 학습했다. 이를 통해 양방향 문맥을 효과적으로 학습할 수 있었다.
BERT의 또 다른 특징은 간단하면서도 강력한 구조이다. BERT는 사전 훈련된 모델에 단일 출력 레이어를 추가하기만 하면 다양한 NLP 작업에 적용할 수 있다. 따라서 복잡한 작업별 아키텍처를 수정할 필요 없이 최첨단 성능을 구현할 수 있었다.
결론적으로, BERT는 기존 NLP 모델의 단방향성 문제를 해결하며 사전 훈련 기반의 양방향 문맥 표현을 학습할 수 있는 새로운 접근 방식을 제시했다. 이를 통해 자연어 추론, 질문 응답, 개체명 인식 등 다양한 작업에서 뛰어난 성능을 발휘하며 NLP 연구와 응용 분야를 혁신적으로 변화시켰다.
Related Work
1. 언어 모델링의 발전

초기의 언어 모델은 주로 n-그램 모델과 같은 통계적 방법론에 의존했다. 이러한 모델은 짧은 문맥만을 고려할 수 있었고, 긴 거리 의존성을 처리하는 데 한계를 가졌다. 이후 등장한 신경망 기반 모델들은 이러한 한계를 일부 극복할 수 있었다. 예를 들어, RNN과 LSTM 모델은 시간적 문맥을 더 잘 포착할 수 있는 구조를 제공했다. 그러나 RNN 계열 모델은 순차적 처리 방식을 사용하기 때문에 병렬 처리에 한계가 있었고, 매우 긴 문맥을 다루는 데는 여전히 어려웠다.
2. 사전 훈련된 언어 모델의 등장
사전 훈련된 언어 모델은 자연어 처리의 중요한 전환점이 되었다. ELMo(Embeddings from Language Models)는 양방향 LSTM을 활용해 문맥에 따라 동적으로 단어 임베딩을 생성한다. 이는 정적인 단어 임베딩 방법인 Word2Vec이나 GloVe와 달리, 같은 단어라도 문맥에 따라 다른 임베딩을 생성할 수 있었다. 그러나 ELMo는 여전히 단어 수준의 임베딩 생성에 머물렀고, 문장의 전반적인 문맥을 포괄적으로 이해하는 데는 제한적이었다.
GPT(Generative Pre-trained Transformer)는 Transformer 아키텍처를 기반으로 한 단방향 언어 모델이다. GPT는 사전 훈련 후 특정 작업에 대해 미세 조정을 수행하여 높은 성능을 보였지만, 입력 텍스트를 단방향으로만 처리했기 때문에 문맥 정볼르 완전히 활용하지 못한다는 한계를 지녔다.
3. Transformer 아키텍처의 도입
Transformer은 Self-Attention 메커니즘을 사용해 입력 텍스트의 문맥을 효과적으로 처리한다. 이 아키텍처는 이전의 RNN 기반의 모델들과 달리, 병렬 처리가 가능하다는 장점이 있다. 이를 통해 대규모 데이터셋에서도 효율적으로 훈련할 수 있었으며, NLP 모델 개발의 기반 기술로 자리 잡았다.
https://seungwoo0407.tistory.com/70
Attention Is All You Need
Transformer의 마지막 공부는 논문을 리뷰하는 것이라고 해서 논문 리뷰하며 공부해보겠습니다. 논문 링크 : https://arxiv.org/pdf/1706.03762작동 과정에 대한 상세 설명 : https://seungwoo0407.tistory.com/68 Transf
seungwoo0407.tistory.com
4. BERT의 차별화된 특징
위에서 언급한 기존 연구들을 기반으로 하여, 이를 더욱 발전시킨 혁신적인 모델로 설계되었다. 먼저, BERT는 기존 모델들과 달리, 모든 레이어에서 입력 텍스트의 왼쪽과 오른쪽 문맥을 동시에 고려하는 양방향 모델이다. 이로 인해 BERT는 문장 수준의 복잡한 문맥을 더욱 잘 이해할 수 있게 되었으며, 특히 질문 응답과 같은 토큰 수준 작업에서 뛰어난 성능을 발휘한다. 또한, BERT는 일부 입력 토큰을 무작위로 마스킹하고, 이를 예측하도록 학습하는 새로운 사전 훈련 목표를 도입했다. 이 방식은 양방향 문맥을 효과적으로 활용할 수 있도록 설계되어, 모델의 언어 이해 능력을 크게 향상시켰다.
5. 전이 학습의 발전
BERT는 전이 학습을 통해 NLP 작업의 효율성을 높였다. 기존의 ELMo와 GPT 역시 사전 훈련 후 특정 작업에 맞게 미세 조정을 수행하는 전이 학습 방법을 사용했지만, BERT는 한 단계 더 발전시켰다. 사전 훈련된 모델에 단일 출력 레이어를 추가하는 방식만으로도 다양한 다운스트림 작업에 쉽게 적용할 수 있도록 설계되었다. 이를 통해 기존의 복잡한 작업별 아키텍처 설계 과정을 단순화 하면서도, 최첨단 성능을 구현할 수 있었다.

해당 그림은 BERT의 두 가지 주요 학습 단계인 사전 훈련과 미세 조정 과정을 시각적으로 나타낸 구조도이다. 먼저, 사전 훈련 단계에서는 대규모 비지도 데이터셋을 사용하여 BERT의 언어 이해 능력을 학습한다. 이 과정은 두 가지 주요 학습 목표로 구성되는데, 첫째로 마스크드 언어 모델(MLM) 방식으로 입력 문장에서 일부 단어를 [MASK]처리한 후 이를 예측하도록 학습하여, 모델이 양방향 문맥 정보를 효과적으로 이해할 수 있도록 한다. 둘째, 다음 문장 예측(NSP)을 통해 두 문장이 문맥적으로 연결되는지 판단하는 능력을 학습한다.
사전 훈련이 완료된 후, 미세 조정 단계에서는 사전 훈련된 BERT를 다양한 자연어처리 작업에 맞게 조정한다. 이 단계에서는 정답이 주어진 데이터셋을 사용하여 특정 작업에 적합한 출력 레이어를 추가하고, 모델을 최적화한다.
BERT 입력 표현

위 이미지는 BERT의 입력 표현에 대한 설명이다. BERT 모델이 텍스트 데이터를 처리하기 위해 입력을 어떻게 준비하는지 보여준다.
먼저, 입력 문장은 토큰화 과정을 거쳐 토큰 단위로 나누고, BERT는 이를 CLS와 SEP 토큰을 포함한 전체 입력 시퀀스로 준비한다.
* CLS : 문장 시작을 나타내는 특수 토큰으로 분류 작업에서 전체 문장의 정보를 요약하는 역할을 한다.
* SEP : 문장 또는 문단의 경계를 나타내는 특수 토큰으로 두 문장 간의 관계를 학습할 때 사용된다.
Token Embeddings에서는 각 토큰은 고정된 차원의 벡터로 변환되고 WordPiece 임베딩을 활용하여 각 단어의 의미를 벡터화한다. 이 벡터는 문맥 정보와 학습을 통해 단어 간의 의미적 관계를 나타낸다.
이후 Segment Embeddings는 문장 A와 문장 B를 구분하기 위해 사용된다. 문장 A의 모든 토큰은 EA로 표현되고, 문장 B의 모든 토큰은 EB로 표현된다. 이는 BERT의 NSP 작업에 필수적인 정보로 활용된다.
Position Embeddings는 Transformer 모델의 구조적 특징상, 입력 토큰의 순서 정보가 필요하기에 토큰의 순서를 나타내기 위해 사용된다. 각 토큰에 고유한 위치 값이 추가되며, 이는 순차적 관계를 학습하는 데 기여한다.
최종 입력 벡터는 토큰 임베딩 + 세그먼트 임베딩 + 위치 임베딩의 합으로 구성된다.
BERT 성능
GLUE 테스트

SQuAD 1.1

SQuAD 2.0

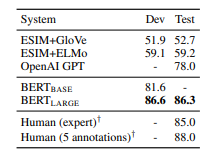
인간과 비교한 성능
NSP를 사용하지 않을 경우 NTR 왼쪽에서 오른쪽으로 학습할 경우 LTR & NO NSP에 BILSTM을 추가한 경우 성능 비교

참고
https://www.youtube.com/watch?v=30SvdoA6ApE
'논문' 카테고리의 다른 글
| Seq2Seq로 Chatbot 구현 (0) | 2025.01.16 |
|---|---|
| LSTM 구현 (1) | 2024.12.17 |
| Attention Is All You Need (0) | 2024.12.10 |
| RNN 구현 (1) | 2024.12.06 |
| Transformer (1) | 2024.12.04 |



