
AI 전문가가 되고싶은 사람
Attention Is All You Need 본문
Transformer의 마지막 공부는 논문을 리뷰하는 것이라고 해서 논문 리뷰하며 공부해보겠습니다.
논문 링크 : https://arxiv.org/pdf/1706.03762
작동 과정에 대한 상세 설명 : https://seungwoo0407.tistory.com/68
Transformer
https://www.youtube.com/watch?v=p216tTVxues Transformer란?2017년 구글 브레인 팀이 발표한 논문으로, 단순히 딥러닝 기술을 넘어 인공지능의 발전에 있어 중요한 이정표로 자리 잡았다. Transformer는 NLP는 물
seungwoo0407.tistory.com
https://www.youtube.com/watch?v=p216tTVxues&t=1163s
서론
1. 배경 및 기존 접근법의 한계
최근 몇 년간, 순환 신경망(RNN), 장단기 메모리 네트워크(LSTM), 그리고 게이트 순환 유닛(GRU)은 언어 모델링 및 기계 번역과 같은 순차 변환 문제에서 최첨단 성능을 보여왔다. 이러한 모델들은 입력 데이터의 순차적 특성을 처리하기에 적합하지만, 계산이 순차적으로 이루어져야 한다는 근본적인 한계가 있다. 이로 인해 병렬화가 어렵고, 긴 시퀀스를 처리할 때 메모리 사용량이 급증하거나 학습이 비효율적으로 이루어질 수 있다.
2. Attention 메커니즘의 등장
Attention 메커니즘은 입력과 출력 시퀀스 간의 의존성을 효과적으로 학습할 수 있는 방법으로 주목받고 있다. 이 메커니즘은 시퀀스 내의 요소 간 거리에 관계없이 중요한 정보의 의존성을 모델링할 수 있어 성능 향상에 기여한다. 그러나 현재 대부분의 Attention 메커니즘은 순환 구조와 결합된 형태로 구현되어, 순환 네트워크의 한계에서 완전히 벗어나지 못하고 있다.
3. 새로운 접근법의 제안
본 논문에서는 기존 순환 구조를 완전히 제거하고, 오직 Attention 메커니즘만으로 입력과 출력 간의 전역 의존성을 모델링하는 Transformer라는 새로운 아키텍처를 제안한다. Transformer는 순환적 계산 없이도 병렬 처리를 극대화할 수 있어, 훈련 효율성과 계산 속도에서 큰 이점을 제공한다. 이러한 혁신적 접근법은 기계 번역 등 다양한 자연어 처리(NLP) 과제에서 최첨단 성능을 달성한다는 것을 실험적으로 증명한다.
Background
1. 순차 계산의 한계
기존의 순차 변환 모델들은 다양한 방식으로 입력과 출력 시퀀스 간의 의존성을 학습해왔다. 특히, 합성곱 신경망(CNN) 기반 모델은 입력 및 출력의 모든 위치에서 병렬 계산이 가능하여 RNN 기반 접근법의 병렬화 한계를 극복하려 했다. 그러나 이러한 모델에서도 두 위치 간 의존성을 연결하는 데 필요한 연산량이 위치 간 거리와 비례해 증가한다는 문제가 여전히 존재한다. 이는 먼 위치 간의 상호작용을 효과적으로 학습하는 데 제약을 초래한다.
2. Self-Attention의 정의 및 역할
Self-Attention 메커니즘은 시퀀스 내의 서로 다른 위치 간 의존성을 계산하여 시퀀스의 표현을 생성하는 강력한 방법론으로 자리 잡았다. 이는 독해, 텍스트 요약, 관계 추론과 같은 다양한 자연어 처리 과제에서 높은 성능을 보이며, 복잡한 관계를 효율적으로 학습할 수 있는 가능성을 보여준다.
3. Transformer의 차별성
Transformer는 기존의 순차 변환 모델들과 달리, RNN이나 CNN을 완전히 배제하고 Self-Attention만을 사용해 입력고 ㅏ출력 시퀀스 간의 표현을 계싼하는 최초의 전이 모델이다. 이를 통해 순차적 계산의 제약에서 벗어나, 먼 거리 간 의존성을 효과적으로 학습하고 병렬화 성능을 극대화하는 혁신적 접근법을 제시한다.
4. 모델 아키텍처와 인코더-디코더 구조
대부분의 순차 변환 모델은 인코더-디코더 구조를 채택하고 있다. 이 구조에서 인코더는 입력 시퀀스를 연속적이고 압축된 표현으로 변환하고, 디코더는 이를 바탕으로 출력 시퀀스를 생성한다. Transformer는 이러한 인코더-디코더 구조를 유지하되, 순차적 계산 대신 Attention 메커니즘을 활용하여 각 위치 간의 의존성을 병렬적으로 학습하고 처리 효율성을 높인다.
Model architecture
Transformer의 구조와 작동 방식은 아래와 같이 Encoder와 Decoder로 구성된 주요 아키텍처 요소롤 포함한다. 각 구성 요소는 효율적이고 유연한 데이터 처리를 가능하게 한다.

인코더는 6개의 동일한 레이어로 구성되며, 각 레이어는 두 개의 서브 레이어를 포함한다. 첫 번째 서브 레이어는 Multi-Head Attention으로 입력 시퀀스의 모든 위치 간 관계를 학습하여 문맥 정보를 이해한다. 두 번째 서브 레이어는 Position-wise Feedforward Network로, 각 위치를 독립적으로 처리하며 입력 데이터를 비선형적으로 변환하여 풍부한 표현을 학습한다. 모든 서브 레이어는 잔차 연결(Residual Connection)과 레이어 정규화(Layer Normalization)를 사용하여 안정성을 유지하며, 서브 레이어의 출력은 입력에 더해지고 정규화 과정을 거친다.
디코더 역시 6개의 동일한 레이어로 구성되며, 인코더와 유사한 구조를 가지고 있다. 하지만 디코더는 세 번째 서브 레이어가 추가 되어 있다. 첫 번째 서브 레이어는 Multi-Head Attention으로, 이전 출력의 정보를 바탕으로 현재 위치의 출력을 생성한다. 이 과정에서 Masking을 적용하여 미래의 정보를 참조하지 않도록 보장한다. 두 번째 서브 레이어는 인코더 출력에 대한 Multi-Head Attention으로 인코더에서 생성된 출력을 참조하여 디코딩 과정에서 필요한 정보를 얻는다. 마지막으로 Position-Wise Feedforward Network는 인코더와 동일하게 동작한다.
Attention 메커니즘은 Transformer에서 핵심적인 역할을 하는데, Attention 메커니즘은 Query, Key, Value 쌍을 입력으로 받아 각 입력 간의 중요도를 계산하고, 이를 기반으로 출력을 생성한다. Scaled Dot-Product Attention는 Query와 Key의 내적을 통해 유사도를 계산하고, 이를 소프트맥스 함수를 적용해 가중치를 생성한다. 가중치는 Value에 곱해져 최종 출력을 생성하며, 계산 안정성을 위해 스케일링이 도입된다.
Multi-Head Attention은 서로 다른 표현 공간에서 정보를 독립적으로 학습하기 위해 여러 개의 Attention Head를 사용한다. 각 Head는 Query, Key, Value를 변환하여 병렬적으로 작동하며, 최종적으로 이들을 연결한 뒤 선형 변환을 통해 하나의 출력으로 결합한다. 이를 통해 다양한 관점에서 입력 시퀀스를 이해할 수 있다.
Transformer는 순차적인 계산을 수행하지 않기 때문에 입력 데이터의 위치 정보를 명시적으로 제공해야한다. 이를 위해 Positional Encoding을 사용하며, 각 입력 임베딩에 위치 정보를 나타내는 벡터를 추가한다. Positional Encoding은 sine과 cosine 함수를 기반으로 위치별 고유 벡터를 생성하며, 모델이 위치 정보를 인식하도록 돕는다.
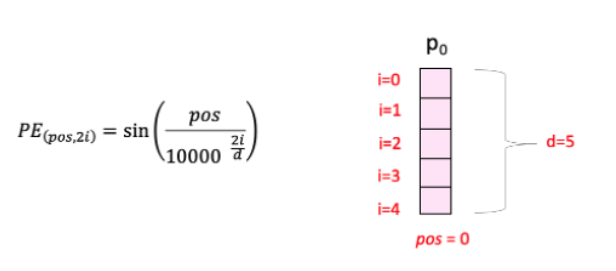
Transformer의 이러한 구조는 병렬 처리를 통해 훈련 속도를 크게 향상시키며, Self-Attention을 통해 입력의 모든 위치 간 관계를 효율적으로 학습할 수 있게 한다. 또한, 모듈형 설계 덕분에 인코더와 디코더 레이어를 손쉽게 확장하거나 수정할 수 있어 기계 번역, 텍스트 요약 등 다양한 NLP 작업에서 높은 성능을 발휘한다고 한다.
Why Self-Attention
Transformer가 Self-Attention 메커니즘을 사용하는 이유는 기존의 신경망 구조, 특히 RNN 및 CNN과 비교했을 때 Self-Attention이 제공하는 독특한 이점 때문이다. Self-Attention은 입력 시퀀스의 모든 위치 간의 관계를 효율적으로 모델링할 수 있는 강력한 메커니즘으로, 이를 통해 Transformer는 다양한 NLP 처리 작업에서 탁월한 성능을 발휘할 수 있다.
먼저, Self-Attention은 NLP와 같은 시퀀스 모델링 작업에서 중요한 장기 의존성을 효과적으로 학습할 수 있다. RNN은 시퀀스의 길이가 길어질수록 이전 상태의 정보를 유지하는 데 어려움을 겪으며, 이로 인해 장기 의존성을 학습하기 어렵다. 반면, Self-Attention은 입력 시퀀스의 모든 위치 간의 관계를 동시에 고려하므로, 시퀀스의 길이에 상관없이 장기 의존성을 효율적으로 학습할 수 있다.
또한, 계산 복잡성 측면에서도 효율적이다. Self-Attention 레이어는 모든 입력 위치 간의 관계를 한 번의 연산으로 계산할 수 있어 상수 시간 내에 처리 가능하지만, RNN은 시퀀스를 순차적으로 처리해야 하므로 계산 복잡도가 시퀀스 길이에 비례 증가한다.
병렬 처리 가능성도 중요한 장점이다. Self-Attention는 입력 시퀀스의 모든 위치를 병렬로 처리할 수 있는 구조를 가지고 있어, 훈련 과정에서 큰 속도 향상을 가져온다. RNN은 순차적으로 데이터를 처리해야 하므로 병렬화가 어렵지만, Self-Attention은 이와 같은 제한 없이 GPU 및 TPU와 같은 하드웨어에서 효율적으로 작동한다.
Self-Attention은 신호 전달 경로가 짧아 경량화된 구조를 제공한다. 입력 시퀀스의 모든 위치 간의 연결이 직접적으로 이루어지기 때문에 정보가 손실될 가능성이 줄어든다. RNN에서는 신호가 여러 단계의 은닉 상태를 거치며 전달되므로, 이 과정에서 정보가 손실되거나 왜곡될 위험이 있지만 Self-Attention 이러한 경로를 최소화하여 안정적이고 정확한 정보 전달을 보장한다.
다양한 표현 학습도 중요한 특징 중 하나이다. Multi-Head Attention을 통해 서로 다른 표현 공간에서 정보를 학습할 수 있으며, 각 헤드는 입력 시퀀스의 서로 다른 부분에 주의를 기울일 수 있다. 이를 통해 모델은 입력 데이터를 다양한 관점에서 이해하며, 더 풍부한 표현을 생성할 수 있다.
마지막으로, 높은 해석 가능성을 제공한다. Self-Attention 메커니즘을 통해 모델은 각 입력 위치가 다른 위치에 얼마나 주의를 기울이는지를 시각화할 수 있으며, 이를 통해 모델의 결정 과정을 분석할 수 있다. 이는 특정 입력이 출력에 미치는 영향을 이해하는 데 유용하며, 모델의 신뢰성을 높이는 데 기여한다.
마무리
Transformer 논문의 5장 이후 내용은 모델의 훈련 과정과 아키텍처, 실험 결과를 다루고 Transformer의 설계 및 성능 향상을 설명한다.
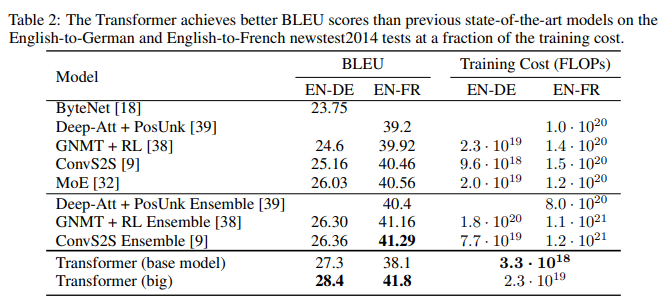
기계 번역 모델의 성능을 평가하는 지표인 BLEU에서 높은 점수를 보이고 있고, 훈련 비용 또한 낮아 더 효율적인 모델임을 의미한다.
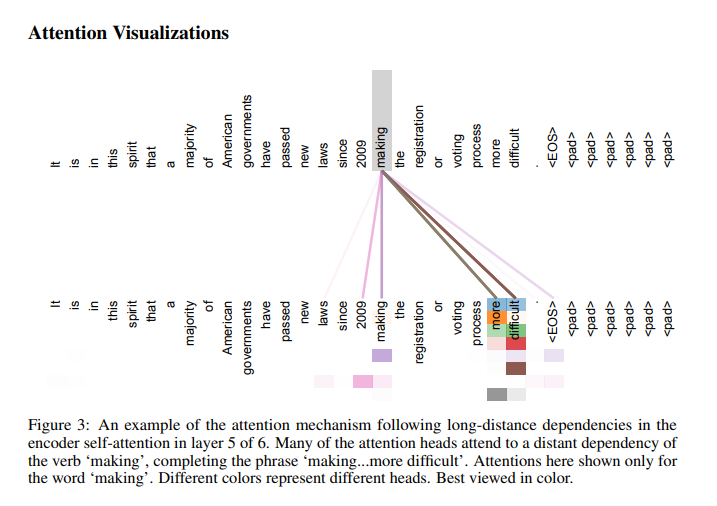
이 이미지는 Transformer 모델의 Self-Attention 메커니즘을 시각화 한 결과를 보여준다. 중심 단어가 making일 때 문장의 다른 단어들에 집중하는 모습을 보여준다. making은 문장의 후반부 단어인 more difficult와 강한 연결을 가지고 있어, making...more difficult이라는 의미적 관계를 완성한다. 다양한 Attention Head가 문장의 서로 다른 부분에 집중하여 단어 간의 다양한 의미적 관계를 학습한다는 것을 보여준다.
장거리 의존성 학습 측면에서 이미지에서 making의 앞부분인 laws와 since뿐 아니라 멀리 떨어진 more과 difficult에도 강하게 연결되는 것이 이를 증명한다.
'논문' 카테고리의 다른 글
| BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding (2) | 2024.12.26 |
|---|---|
| LSTM 구현 (1) | 2024.12.17 |
| RNN 구현 (1) | 2024.12.06 |
| Transformer (1) | 2024.12.04 |
| Seq2seq+Attention (0) | 2024.11.25 |



